


Our Approach
We provide Virtual Engineers that help you to maximise the bottom line for your industrial machines, or to increase the operational life of your infrastructure. These are pre-made and pre-configured packages, as we believe that you shouldn't be engineering an optimal setup, find out what to measure and fiddle with data connectors yourself. Don't loose time on finding what model works best and how to train it (or re-train it when something changed on the asset), but get up-and-running as fast as possible.
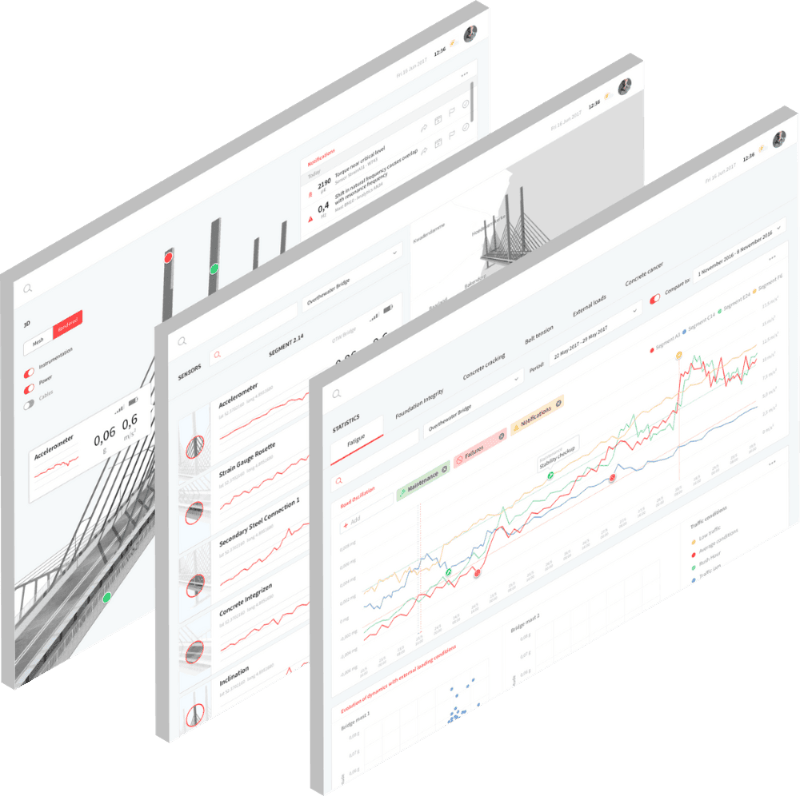

A suite of dedicated monitoring solutions for specific machines, installations and structures: Virtual Engineers
Components of each product:
- Data collection
- Automated analysis: a set of connected algorithms looking at multiple aspects of relevance related to health, integrity, efficiency, quality...
- Algorithms for interpretation and contextualization
- Visualization on asset-specific dashboards
- Warnings and Alarms
Easy and fast:
- Fast to deploy
- Short time to value
- No DIY
- User-based access rights
- All data and insights represented in a single environment
- No interference with running operations or existing systems
Simple and straightforward:
- A tool to manage all relevant aspects of an installation: state-of-health, efficiency, product quality, remaining lifetime
- A focus on simplicity: allow non-expert colleagues to also consult insights based on the treated data
- Pre-configured, clear and structured dashboards, grouped based on site and asset in a logical way








